

Introduction
Statistics forms the back bone of data science or any analysis for that matter. Sound knowledge of statistics can help an analyst to make sound business decisions.
On one hand, descriptive statistics helps us to understand the data and its properties by use of central tendency and variability. On the other hand, inferential statistics helps us to infer properties of the population from a given sample of data. Knowledge of both descriptive and inferential statistics is essential for an aspiring data scientist or analyst.
To help you improve your knowledge in statistics we conducted this practice test. The test covered both descriptive and inferential statistics in brief. I am providing the answers with explanation in case you got stuck on particular questions.
In case you missed the test, try solving the questions before reading the solutions.
Overall Scores
Below are the distribution scores, they will help you evaluate your performance.
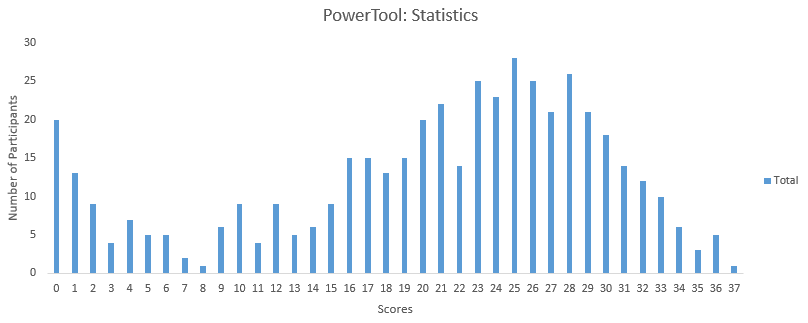
You can access the final scores here. More than 450 people took this test and the highest score obtained was 37. Here are a few statistics about the distribution.
Mean Score: 20.40
Median Score: 23
Mode Score: 25
Questions & Solution
1) Which of these measures are used to analyze the central tendency of data?
A) Mean and Normal Distribution
B) Mean, Median and Mode
C) Mode, Alpha & Range
D) Standard Deviation, Range and Mean
E) Median, Range and Normal Distribution
Solution: (B)
The mean, median, mode are the three statistical measures which help us to analyze the central tendency of data. We use these measures to find the central value of the data to summarize the entire data set.
2) Five numbers are given: (5, 10, 15, 5, 15). Now, what would be the sum of deviations of individual data points from their mean?
A) 10
B)25
C) 50
D) 0
E) None of the above
Solution: (D)
The sum of deviations of the individual will always be 0.
3) A test is administered annually. The test has a mean score of 150 and a standard deviation of 20. If Ravi’s z-score is 1.50, what was his score on the test?
A) 180
B) 130
C) 30
D) 150
E) None of the above
Solution: (A)
X= μ+Zσ where μ is the mean, σ is the standard deviation and X is the score we’re calculating. Therefore X = 150+20*1.5 = 180
4) Which of the following measures of central tendency will always change if a single value in the data changes?
A) Mean
B) Median
C) Mode
D) All of these
Solution: (A)
The mean of the dataset would always change if we change any value of the data set. Since we are summing up all the values together to get it, every value of the data set contributes to its value. Median and mode may or may not change with altering a single value in the dataset.
5) Below, we have represented six data points on a scale where vertical lines on scale represent unit.
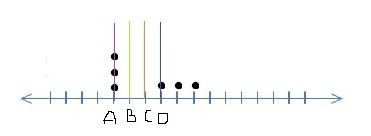
Which of the following line represents the mean of the given data points, where the scale is divided into same units?
A) A
B) B
C) C
D) D
Solution: (C)
It’s a little tricky to visualize this one by just looking at the data points. We can simply substitute values to understand the mean. Let A be 1, B be 2, C be 3 and so on. The data values as shown will become {1,1,1,4,5,6} which will have mean to be 18/6 = 3 i.e. C.
6) If a positively skewed distribution has a median of 50, which of the following statement is true?
A) Mean is greater than 50
B) Mean is less than 50
C) Mode is less than 50
D) Mode is greater than 50
E) Both A and C
F) Both B and D
Solution: (E)
Below are the distributions for Negatively, Positively and no skewed curves.
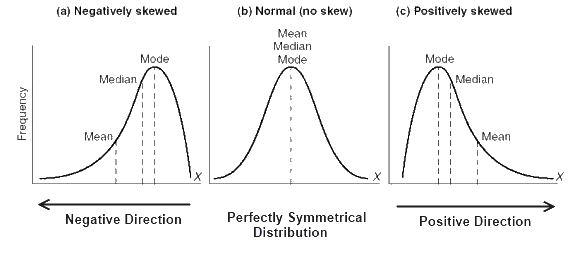
As we can see for a positively skewed curve, Mode<Median<Mean. So if median is 50, mean would be more than 50 and mode will be less than 50.
7) Which of the following is a possible value for the median of the below distribution?
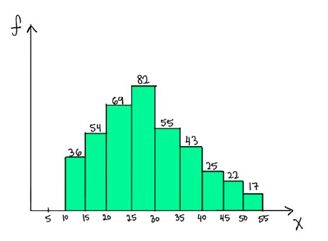
A) 32
B) 26
C) 17
D) 40
Solution: (B)
To answer this one we need to go to the basic definition of a median. Median is the value which has roughly half the values before it and half the values after. The number of values less than 25 are (36+54+69 = 159) and the number of values greater than 30 are (55+43+25+22+17= 162). So the median should lie somewhere between 25 and 30. Hence 26 is a possible value of the median.
8) Which of the following statements are true about Bessels Correction while calculating a sample standard deviation?
- Bessels correction is always done when we perform any operation on a sample data.
- Bessels correction is used when we are trying to estimate population standard deviation from the sample.
- Bessels corrected standard deviation is less biased.
A) Only 2
B) Only 3
C) Both 2 and 3
D) Both 1 and 3
Solution: (C)
Contrary to the popular belief Bessel’s correction should not be always done. It’s basically done when we’re trying to estimate the population standard deviation using the sample standard deviation. The bias is definitely reduced as the standard deviation will now(after correction) be depicting the dispersion of the population more than that of the sample.
9) If the variance of a dataset is correctly computed with the formula using (n – 1) in the denominator, which of the following option is true?
A) Dataset is a sample
B) Dataset is a population
C) Dataset could be either a sample or a population
D) Dataset is from a census
E) None of the above
Solution: (A)
If the variance has n-1 in the formula, it means that the set is a sample. We try to estimate the population variance by dividing the sum of squared difference with the mean with n-1.
When we have the actual population data we can directly divide the sum of squared differences with n instead of n-1.
10) [True or False] Standard deviation can be negative.
A) TRUE
B) FALSE
Solution: (B)
Below is the formula for standard deviation
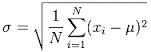
Since the differences are squared, added and then rooted, negative standard deviations are not possible.
11) Standard deviation is robust to outliers?
A) True
B) False
Solution: (B)
If you look at the formula for standard deviation above, a very high or a very low value would increase standard deviation as it would be very different from the mean. Hence outliers will effect standard deviation.
12) For the below normal distribution, which of the following option holds true ?
σ1, σ2 and σ3 represent the standard deviations for curves 1, 2 and 3 respectively.

A) σ1> σ2> σ3
B) σ1< σ2< σ3
C) σ1= σ2= σ3
D) None
Solution: (B)
From the definition of normal distribution, we know that the area under the curve is 1 for all the 3 shapes. The curve 3 is more spread and hence more dispersed (most of values being within 40-160). Therefore it will have the highest standard deviation. Similarly, Curve 1 has a very low range and all the values are in a small range of 80-120. Hence, curve 1 has the least standard deviation.
13) What would be the critical values of Z for 98% confidence interval for a two-tailed test ?
A) +/- 2.33
B) +/- 1.96
C) +/- 1.64
D) +/- 2.55
Solution: (A)
We need to look at the z table for answering this. For a 2 tailed test, and a 98% confidence interval, we should check the area before the z value as 0.99 since 1% will be on the left side of the mean and 1% on the right side. Hence we should check for the z value for area>0.99. The value will be +/- 2.33
14) [True or False] The standard normal curve is symmetric about 0 and the total area under it is 1.
A)TRUE
B) FALSE
Solution: (A)
By the definition of the normal curve, the area under it is 1 and is symmetric about zero. The mean, median and mode are all equal and 0. The area to the left of mean is equal to the area on the right of mean. Hence it is symmetric.
Context for Questions 15-17
Studies show that listening to music while studying can improve your memory. To demonstrate this, a researcher obtains a sample of 36 college students and gives them a standard memory test while they listen to some background music. Under normal circumstances (without music), the mean score obtained was 25 and standard deviation is 6. The mean score for the sample after the experiment (i.e With music) is 28.
15) What is the null hypothesis in this case?
A) Listening to music while studying will not impact memory.
B) Listening to music while studying may worsen memory.
C) Listening to music while studying may improve memory.
D) Listening to music while studying will not improve memory but can make it worse.
Solution: (D)
The null hypothesis is generally assumed statement, that there is no relationship in the measured phenomena. Here the null hypothesis would be that there is no relationship between listening to music and improvement in memory.
16) What would be the Type I error?
A) Concluding that listening to music while studying improves memory, and it’s right.
B) Concluding that listening to music while studying improves memory when it actually doesn’t.
C) Concluding that listening to music while studying does not improve memory but it does.
Solution: (B)
Type 1 error means that we reject the null hypothesis when its actually true. Here the null hypothesis is that music does not improve memory. Type 1 error would be that we reject it and say that music does improve memory when it actually doesn’t.
17) After performing the Z-test, what can we conclude ____ ?
A) Listening to music does not improve memory.
B)Listening to music significantly improves memory at p
C) The information is insufficient for any conclusion.
D) None of the above
Solution: (B)
Let’s perform the Z test on the given case. We know that the null hypothesis is that listening to music does not improve memory.
Alternate hypothesis is that listening to music does improve memory.
In this case the standard error i.e. ![]()
The Z score for a sample mean of 28 from this population is
![]()
Z critical value for α = 0.05 (one tailed) would be 1.65 as seen from the z table.
Therefore since the Z value observed is greater than the Z critical value, we can reject the null hypothesis and say that listening to music does improve the memory with 95% confidence.
18) A researcher concludes from his analysis that a placebo cures AIDS. What type of error is he making?
A) Type 1 error
B) Type 2 error
C) None of these. The researcher is not making an error.
D) Cannot be determined
Solution: (D)
By definition, type 1 error is rejecting the null hypothesis when its actually true and type 2 error is accepting the null hypothesis when its actually false. In this case to define the error, we need to first define the null and alternate hypothesis.
19) What happens to the confidence interval when we introduce some outliers to the data?
A) Confidence interval is robust to outliers
B) Confidence interval will increase with the introduction of outliers.
C) Confidence interval will decrease with the introduction of outliers.
D) We cannot determine the confidence interval in this case.
Solution: (B)
We know that confidence interval depends on the standard deviation of the data. If we introduce outliers into the data, the standard deviation increases, and hence the confidence interval also increases.
Context for questions 20- 22
A medical doctor wants to reduce blood sugar level of all his patients by altering their diet. He finds that the mean sugar level of all patients is 180 with a standard deviation of 18. Nine of his patients start dieting and the mean of the sample is observed to 175. Now, he is considering to recommend all his patients to go on a diet.
Note: He calculates 99% confidence interval.
What is the standard error of the mean?






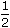 :
: 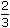 :
: 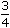 , then the first part is:
, then the first part is: